1. 下载软件
git clone https://github.com/tanghaibao/jcvi.git
cd jcvi
conda env create -f environment.yml
2. 准备输入文件
将gff文件转换为jcvi指定的bed文件,我在练习的时候是用3个物种进行联系,所以后续的代码都是以这三个物种的微共线性分析进行的/
python3 -m jcvi.formats.gff bed --type=mRNA Bsap.gff -o Bsap.bed
python3 -m jcvi.formats.gff bed --type=mRNA Daod.gff -o Daod.bed
python3 -m jcvi.formats.gff bed --type=mRNA Dcul.gff -o Dcul.bed
3. 微共线性分析
3.1 鉴定共线性区块
注:要选定一个参考物种,随后其他物种均与参考物种鉴定共线性区块,本次选择的是Daod这个物种。此外,这一步输入文件必须是在当前文件下可以直接找到的.cds和.bed文件的,例如输入的Daod,软件就会在当前文件夹寻找Daod.cds和Daod.bed.
python3 -m jcvi.compara.catalog ortholog Daod Bsap --no_strip_names
python3 -m jcvi.compara.catalog ortholog Daod Dcul --no_strip_names
3.2 提取1对1的共线性区块
python -m jcvi.compara.synteny mcscan Daod.bed Daod.Bsap.lifted.anchors --iter=1 -o Daod.Bsap.block
python -m jcvi.compara.synteny mcscan Daod.bed Daod.Dcul.lifted.anchors --iter=1 -o Daod.Dcul.block
3.3 合并多个物种和参考物种的共线性区块文件
paste Daod.Bsap.block Daod.Dcul.block|cut -f 1,2,4 > Combine.block
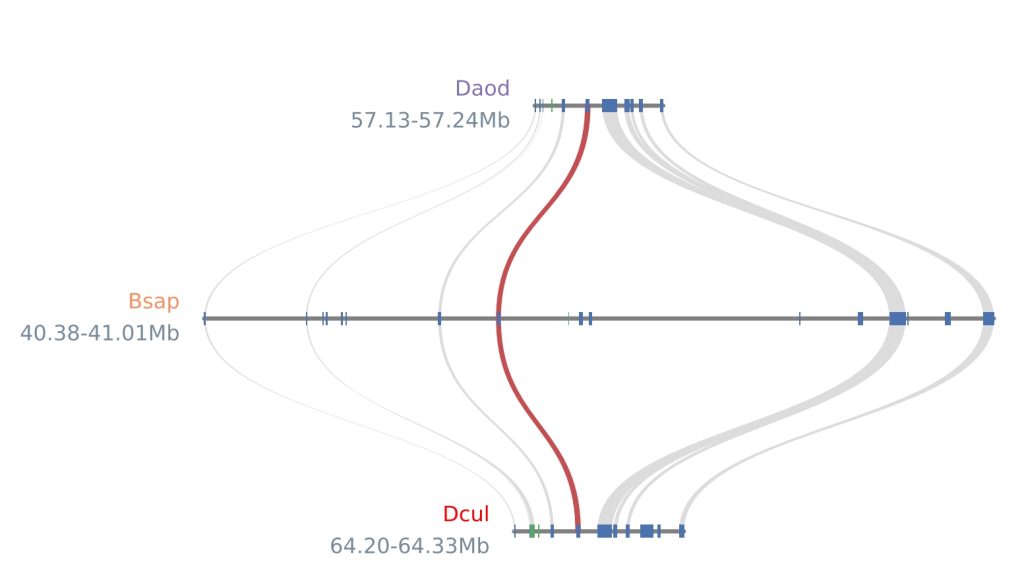
3.4 提取目的基因及其前后5个基因
grep -C 5 "Daodo07aG0604400" Combine.block > Daodo07aG0604400.block
3.5 合并所有的bed文件
python -m jcvi.formats.bed merge Daod.bed Bsap.bed Dcul.bed -o Combine.bed
3.6 绘制微共线性图
python -m jcvi.graphics.synteny Daodo07aG0604400.block Combine.bed block.layout --outputprefix Daodo07aG0604400
以下为配置文件“block.layout”的格式
x, y, rotation, ha, va, color, ratio, label
0.5, 0.6, 0, left, center, m, 1, Daod
0.5, 0.4, 0, left, center, #fc8d62, 1, Bsap
0.5, 0.2, 0, left, center, red, 1, Dcul
# edges
e, 0, 1
e, 1, 2